一文详解 MyCAT分库分表、读写分离、主备切换三大功能

文章共 1796字,阅读大约需要 4分钟 !
概 述
在如今海量数据充斥的互联网环境下,分库分表的意义我想在此处就不用赘述了。而分库分表目前流行的方案最起码有两种:
- 方案一:基于应用层的分片,即应用层代码直接完成分片逻辑
- 方案二:基于代理层的分片,即在应用代码和底层数据库中间添加一层代理层,而分片的路由规则则由代理层来进行处理
而本文即将要实验的 MyCAT框架就属于第二种方案的代表作品。
注: 本文首发于 My Personal Blog:CodeSheep·程序羊,欢迎光临 小站
环境规划
在本文中,我拿出了三台 Linux主机投入试验,各节点的角色分配如下表所示:
| 节点 | 部署组件 | 角色 |
|---|---|---|
| 192.168.199.75 | MySQL 、 MyCAT | master |
| 192.168.199.74 | MySQL | slave |
| 192.168.199.76 | MySQL | standby master |
如果说上面这张表不足以说明实验模型,那接下来再给一张图好了,如下所示:
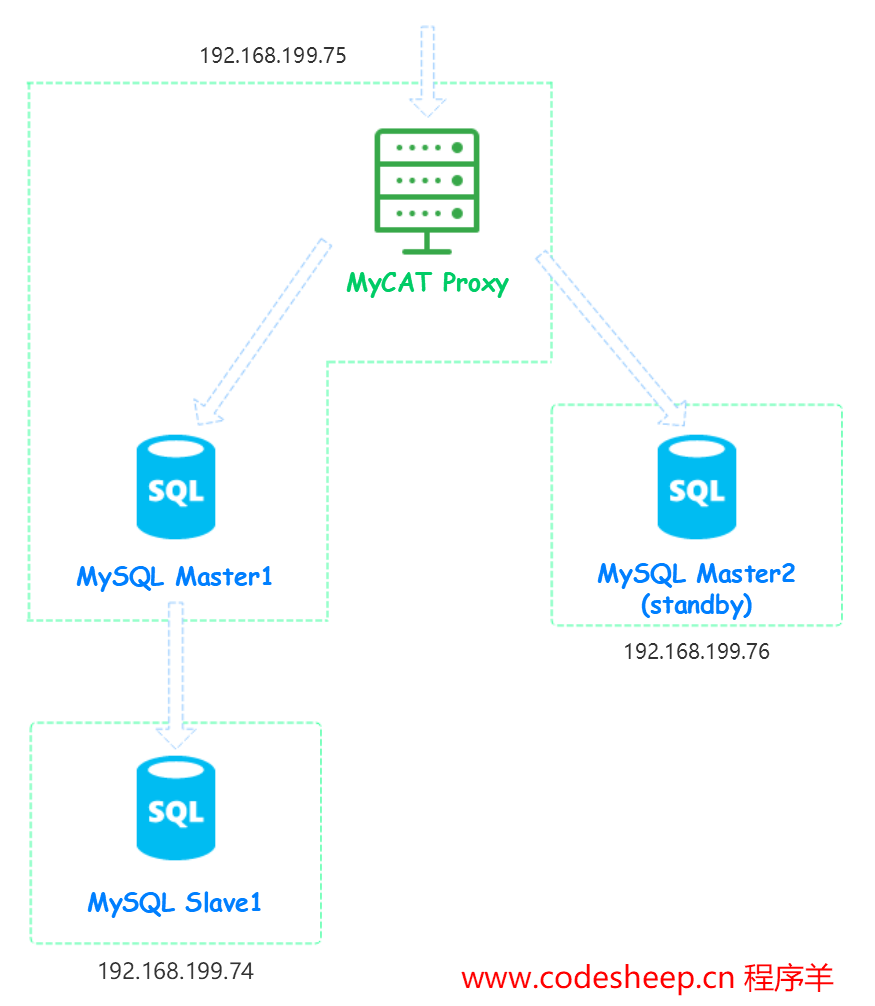
我想这样看来的话,各个节点布了哪些组件,节点间的角色关系应该一目了然了吧
实验环境规划好了以后,接下来进行具体的部署与实验过程,首先当然是 MyCAT代理的部署
MyCAT 部署
关于该部分,网上教程实在太多了,但最好还是参考官方文档来吧,下面也简述一下部署过程
- 下载 MyCAT并解压安装
这里安装的是 MyCAT 1.5
1 | wget https://raw.githubusercontent.com/MyCATApache/Mycat-download/master/1.5-RELEASE/Mycat-server-1.5.1-RELEASE-20161130213509-linux.tar.gz |
- 启动 MyCAT
1 | ./mycat start |

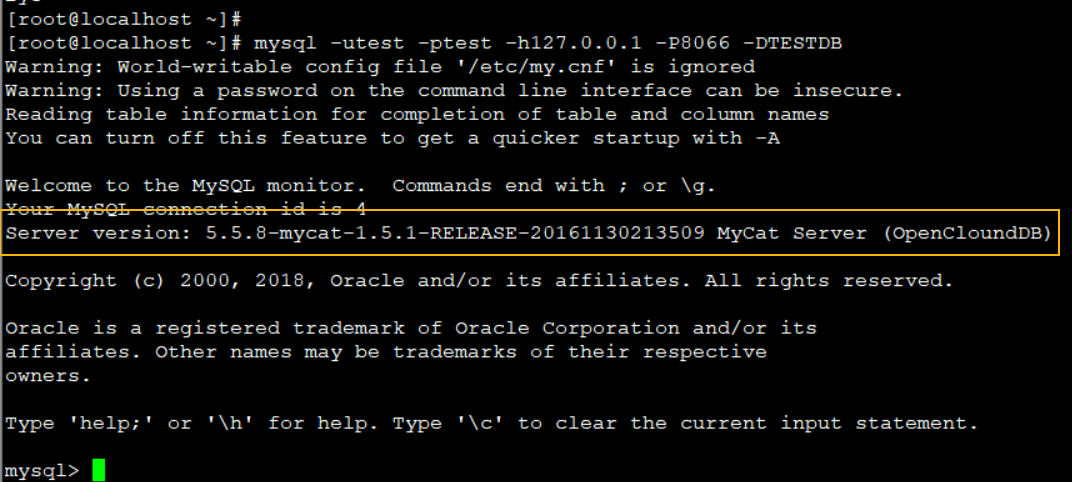
- MyCAT连接测试
1 | mysql -utest -ptest -h127.0.0.1 -P8066 -DTESTDB |
MyCAT 配置
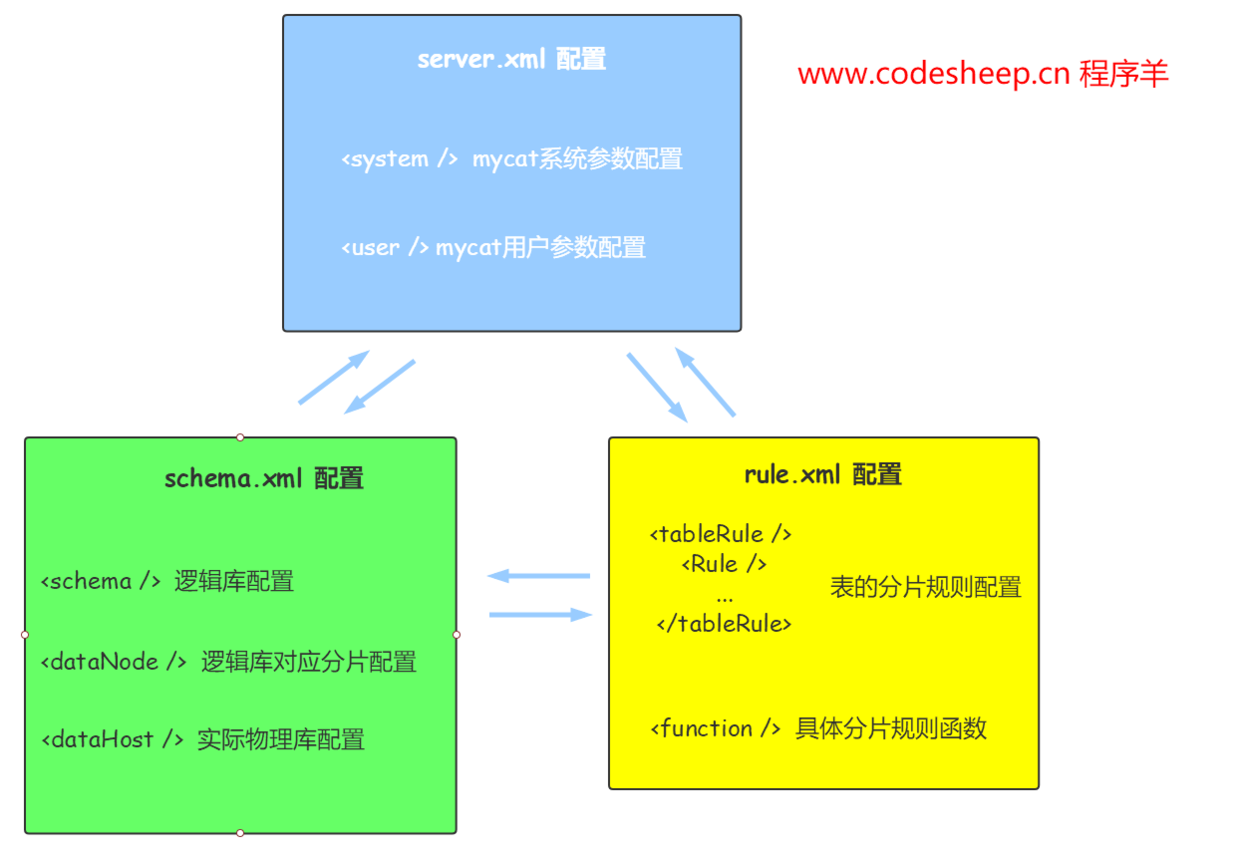
官网上对于这一部分的描述是非常详细的,MyCAT 配置主要涉及三个 XML配置文件:
server.xml:MyCAT框架的系统参数/用户参数配置文件schema.xml: MyCAT框架的逻辑库表与分片的配置文件rule.xml:MyCAT框架的逻辑库表分片规则的配置文件
用如下图形可以形象地表示出这三个 XML配置文件的配置内容和相互关系:
下面来进入具体的实验环节 ,这也是围绕 MyCAT提供的几大主要功能展开的,主要涉及三个方面
- 分库分表
- 读写分离
- 主备切换
实验之前,我们先给出公共的 server.xml文件的配置,这部分后续实验过程中并不修改,其也就是定义了系统参数和用户参数:
1 | <?xml version="1.0" encoding="UTF-8"?> |
分库分表实验
预期实验效果:通过 MyCAT代理往一张逻辑表中插入的多条数据,在后端自动地分配在不同的物理数据库表上
我们按照本文 第二节【环境规划】中给出的实验模型图来给出如下的 MyCAT逻辑库配置文件 schema.xml 和 分库分表规则配置文件 rule.xml
- 准备配置文件
schema.xml
1 | <?xml version="1.0"?> |
其中定义了实验用到的 hostM1、hostS1 和 hostM2
rule.xml1
2
3
4
5
6
7
8
9
10
11
12<tableRule name="sharding-by-month">
<rule>
<columns>create_date</columns>
<algorithm>partbymonth</algorithm>
</rule>
</tableRule>
<function name="partbymonth"
class="org.opencloudb.route.function.PartitionByMonth">
<property name="dateFormat">yyyy-MM-dd</property>
<property name="sBeginDate">2018-11-01</property>
</function>
这里配置了
sharding-by-month的分库分表规则,即按照表中的create_date字段进行分割,从2018-11-01日期开始,月份不同的数据落到不同的物理数据库表中
- 在三个物理节点数据库上分别创建两个库 db1和 db2
1 | create database db1; |
- 连接 MyCAT
1 | mysql -utest -ptest -h127.0.0.1 -P8066 -DTESTDB |
- 通过 MyCAT来创建数据库
travelrecord
1 | create table travelrecord (id bigint not null primary key,city varchar(100),create_date DATE); |
- 通过 MyCAT来往
travelrecord表中插入两条数据
1 | insert into travelrecord(id,city,create_date) values(1,'NanJing','2018-11-3'); |
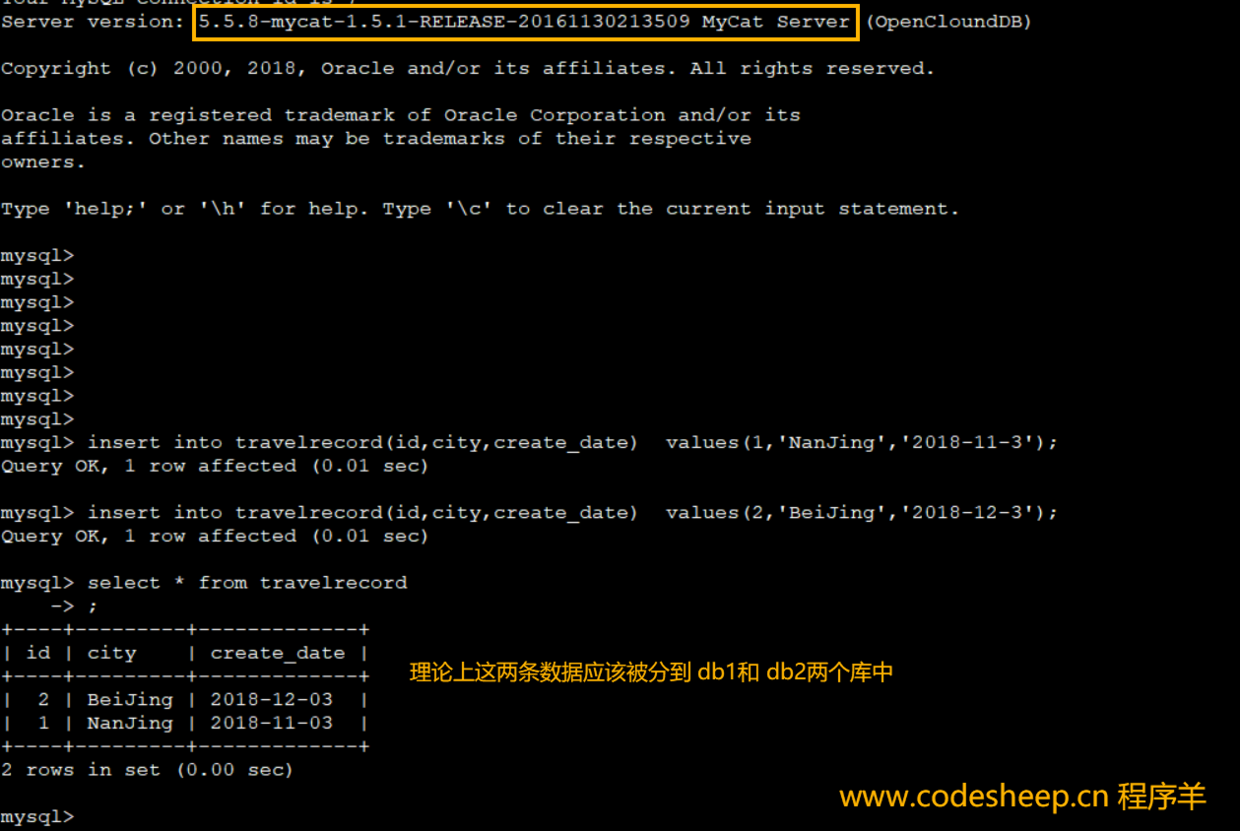
由于插入的这两条记录的 create_date分别是 2018-11-3和 2018-12-3,而我们配的分库分表的规则即是根据 2018-11-01这个日期为起始来进行递增的,按照前面我们配的分片规则,理论上这两条记录按照 create_date日期字段的不同,应该分别插入到 hostM1的 db1和 db2两个不同的数据库中。
- 验证一下数据分片的效果
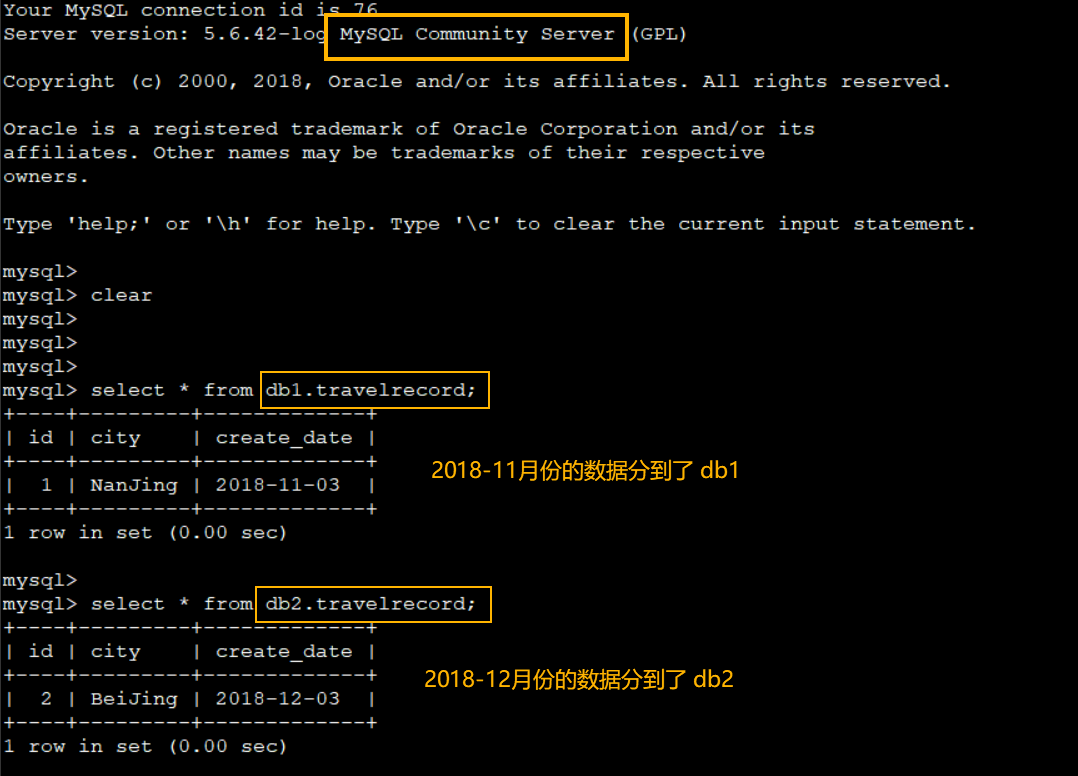
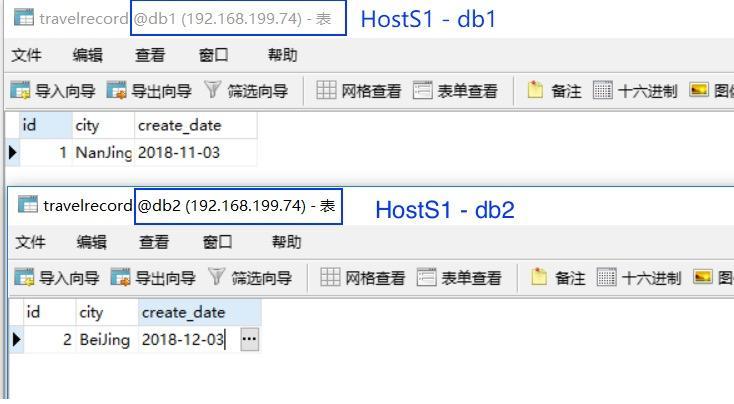
由于 hostM1和 hostS1组成了 主-从库 关系,因此刚插入的两条数据也应该相应自动同步到 hostS1的 db1和 db2两个数据库中,不妨也来验证一下:
读写分离实验
预期实验效果:开启了 MyCAT的读写分离机制后,读写数据操作各行其道,互不干扰
此节实验用到的配置文件 schema.xml 和 rule.xml基本和上面的【分库分表】实验没什么不同,只是我们需要关注一下 schema.xml配置文件中 <dataHost />标签里的 balance字段,它是与读写分离息息相关的配置:
因此我们就需要弄清楚
balance="0":不开启读写分离机制,即读请求仅分发到 writeHost上balance="1":读请求随机分发到当前 writeHost对应的 readHost和 standby writeHost上balance="2":读请求随机分发到当前 dataHost内所有的 writeHost / readHost上balance="3":读请求随机分发到当前 writeHost对应的 readHost上
我们验证一下 balance="1"的情况,即开启读写分离机制,且读请求随机分发到当前 writeHost对应的 readHost和 standby writeHost上,而对于本文来讲,也即:hostS1 和 hostM2 上
我们来做两次数据表的 SELECT读操作:
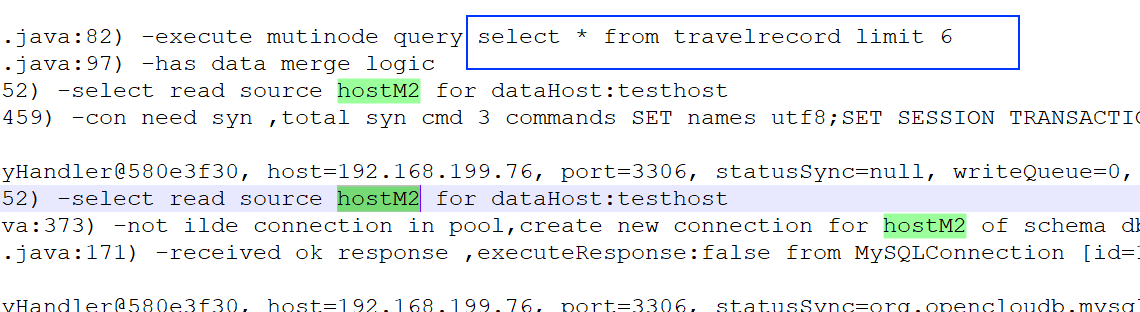
1 | mysql> select * from travelrecord limit 6; |
然后我们取出 mycat.log日志查看一下具体详情,我们发现第一次 select读操作分发到了 hostM2上:
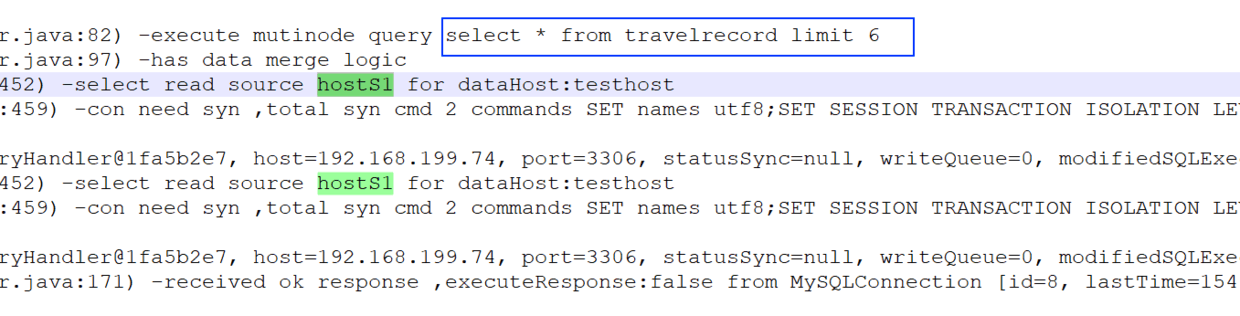
而第二次 select读操作分发到了 hostS1上:
主备切换实验
预期实验效果:开启 MyCAT的主备机制后,当主库宕机时,自动切换到备用机进行操作
关于主备切换,则需要弄清楚 <dataHost /> 标签中 switchType参数的含义:
switchType="-1":不自动切换主备数据库switchType="1":自动切换主备数据库switchType="2":基于MySQL主从复制的状态来决定是否切换,需修改heartbeat语句:show slave statusswitchType="3":基于Galera(集群多节点复制)的切换机制,需修改heartbeat语句:show status like 'wsrep%'
此处验证一下 Mycat的主备自动切换效果。为此首先我们将 switchType="-1" 设置为 switchType="1",并重启 MyCat服务:
1 | <dataHost name="testhost" maxCon="1000" minCon="10" balance="0" |
在本实验环境中,在 hostM1 和 hostM2均正常时,默认写数据时是写到 hostM1的
- 接下来手动停止 hostM1 上的 MySQL数据库来模拟 hostM1 宕机:
1 | systemctl stop mysqld.service |
接下来再通过 MyCat插入如下两条数据:
1 | insert into travelrecord(id,city,create_date) values(3,'TianJing','2018-11-4'); |
效果如下:
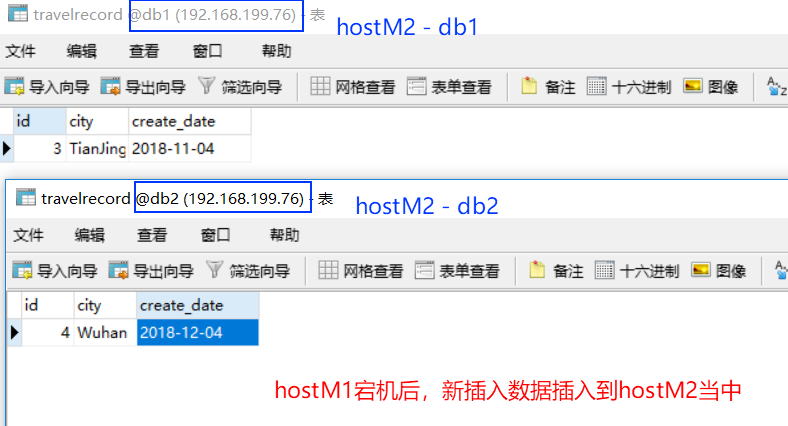
- 此时,我们恢复 hostM1,但接下来的数据写入依然进入 hostM2
1 | insert into travelrecord(id,city,create_date) values(5,'ShenYang','2018-11-5'); |
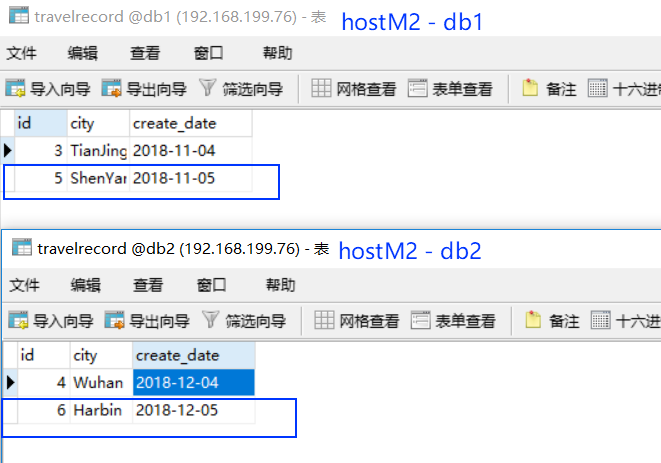
- 接下来手动让 hostM2宕机,看 hostM1 是否能升级为主写节点
再插入两条数据:
1 | insert into travelrecord(id,city,create_date) values(7,'SuZhou','2018-11-6'); |
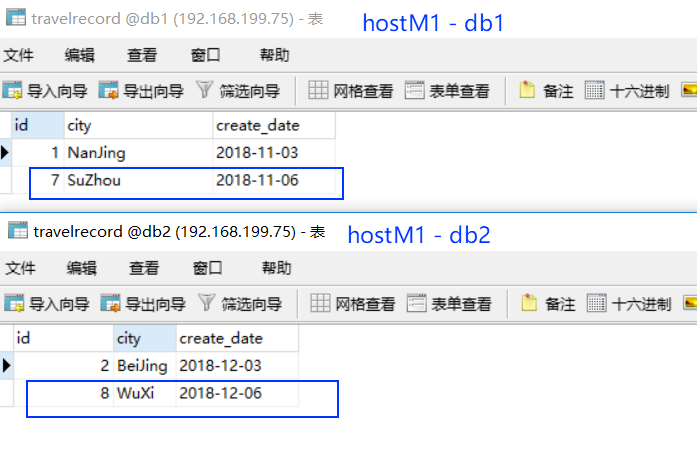
很明显,答案是肯定的
后 记
由于能力有限,若有错误或者不当之处,还请大家批评指正,一起学习交流!
- My Personal Blog:CodeSheep 程序羊
- 我的半年技术博客之路
 支付宝打赏
支付宝打赏  微信打赏
微信打赏